n8n 工作流 - supabase & RAG 知识库
之前有学习实践写过一个 LLM + MCP + RAG 实现极简 Agent 客户端(不依赖框架)的项目
https://github.com/fxpby/llm-mcp-rag-demo
写代码运行项目有一定的学习成本和环境需求在,最近开始探索 n8n 这块,不敲代码也能构建云上工作流,感觉很方便吧,一起来耍一下~
我们的目标是制作一个基于 Supabase 向量存储的 n8n RAG 知识库管理与问答工作流
1. 创建 supabase 向量存储项目
正好前两天探索的 supabase 这款云端数据库产品对 AI 相关生态十分友好,也支持向量数据存储,这次用它来存储项目文档数据
来到 https://supabase.com/ 注册一个账号,同时创建一个组织,并创建一个 project,选择区域的时候建议选择距离自己较近的地方
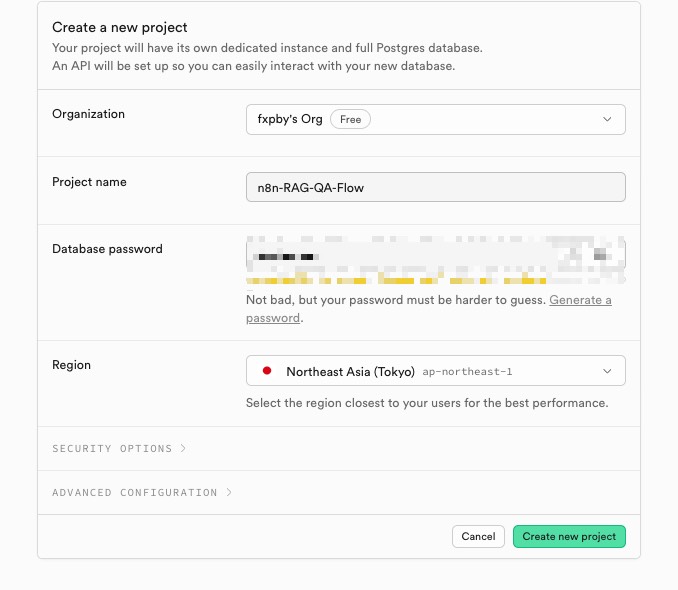
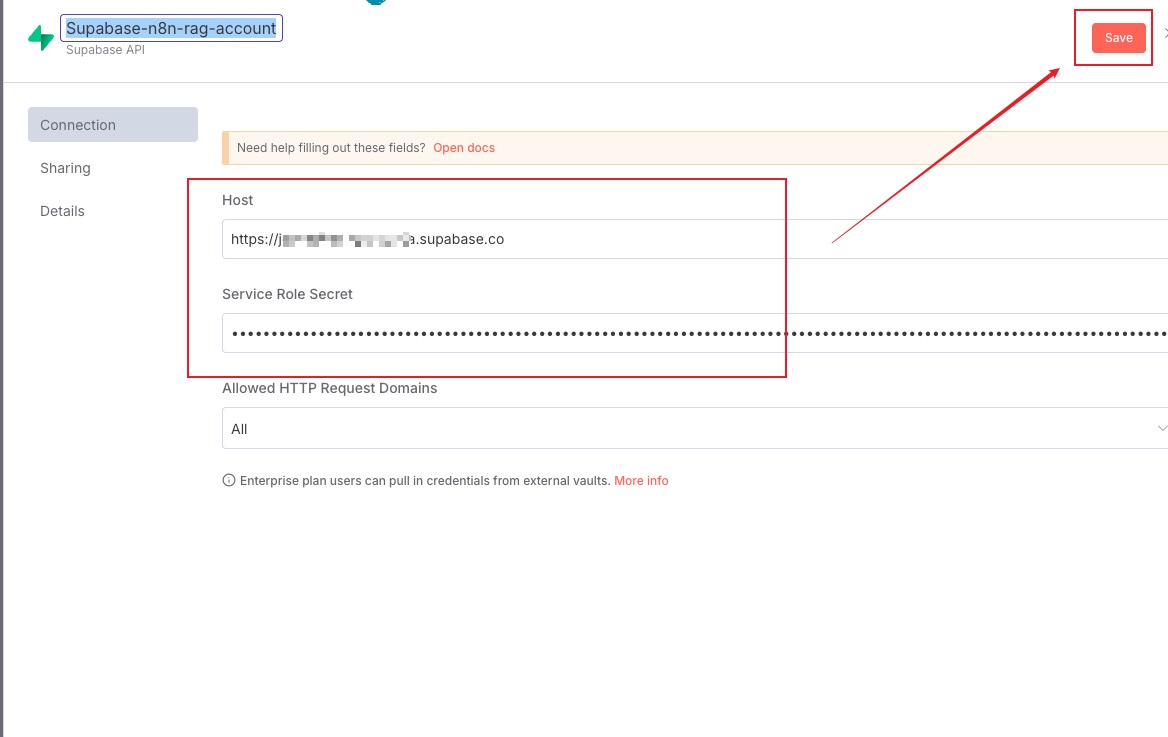
再来到控制面板的 Settings 页面,看到有一个 Data API,点击右侧会有项目 URL,在 n8n 工作流中,创建 Supabase 向量存储时会用到这个 URL,可以先保存一下
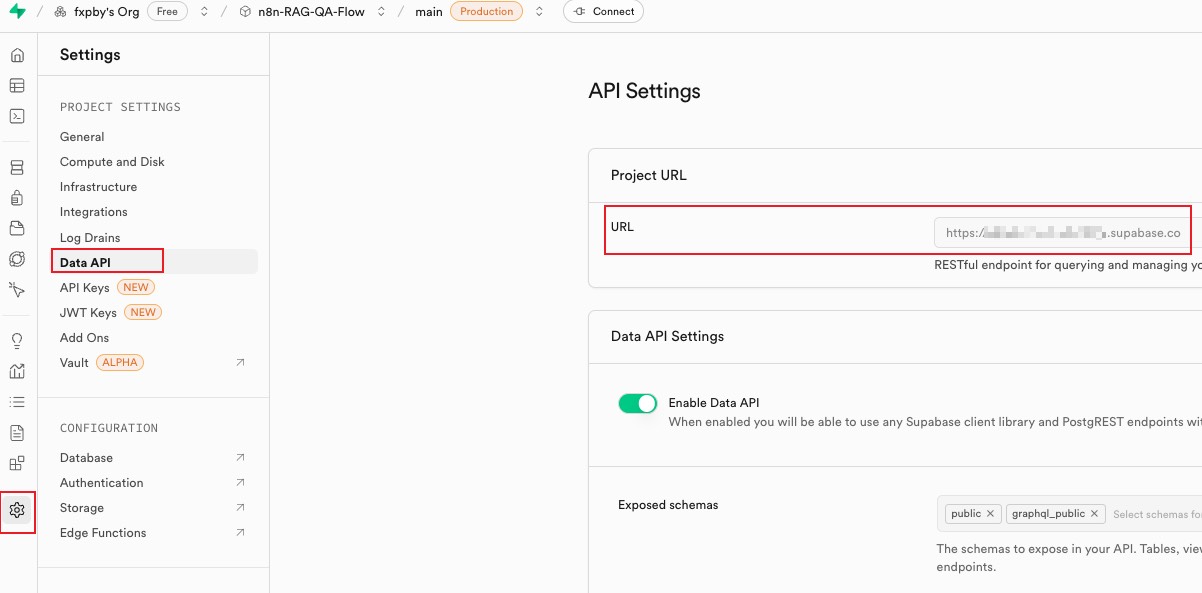
同样在 API Keys 中有一个 service role,这个后面配置中也会用到,可以保存一下
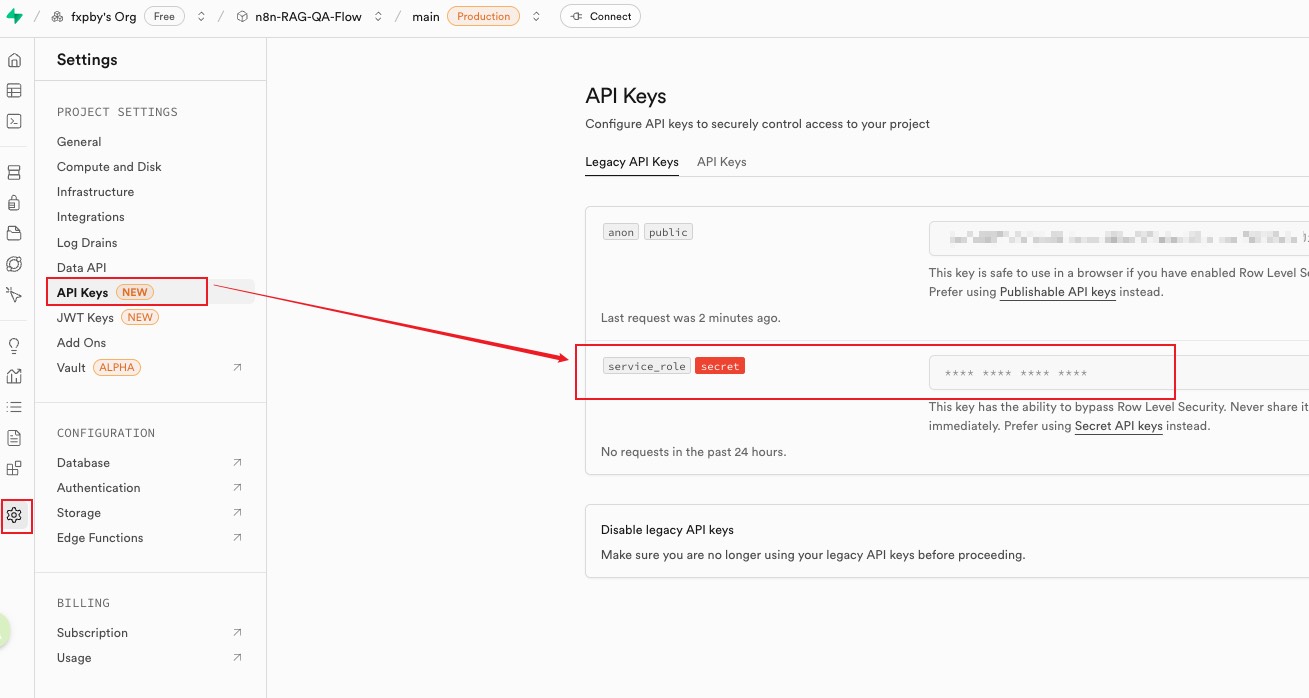
在官方文档 https://supabase.com/docs/guides/ai/langchain 中有一个 LangChain 的文档,LangChain 支持使用 supabase 作为向量存储,我们需要下面的 SQL 代码来初始化数据库
这里有一个点需要注意下,示例代码中我们有看到 1536 这个容积值,后面我们选 embedding 模型时也需要注意要配套一致,否则会报错,类似Error inserting: expected 1536 dimensions, not 4096 400 Bad Request
根据手头模型来,模型 dimensions 是多少,这里的 SQL 就写多少
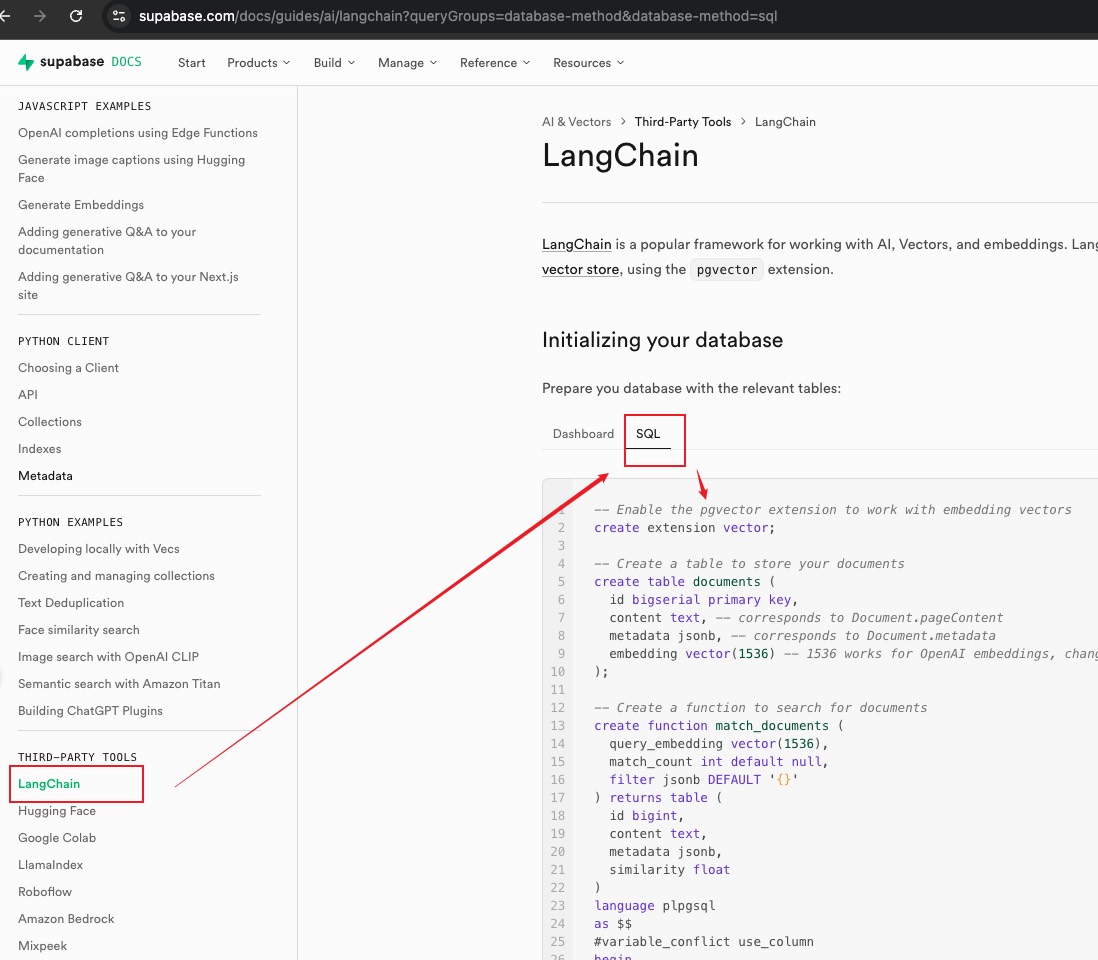
来到 supabase 项目的控制面板,在 SQL Editor 中粘贴上面的 SQL 代码,并点击运行
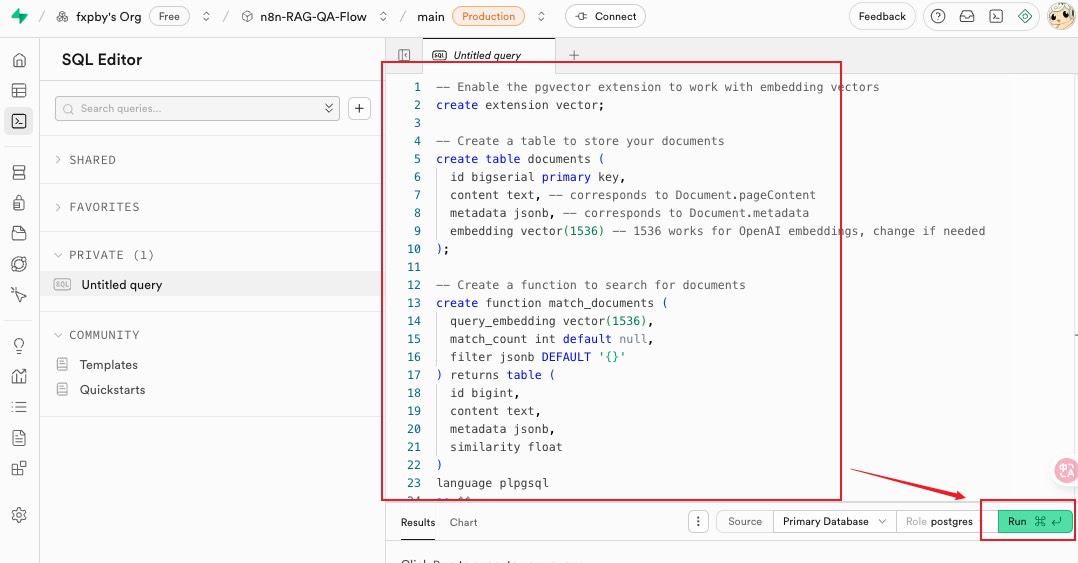
执行成功下面 result 面板会显示 Success. No rows returned
来到控制面板 Database - Tables 中可以看到撞击的 documents 表
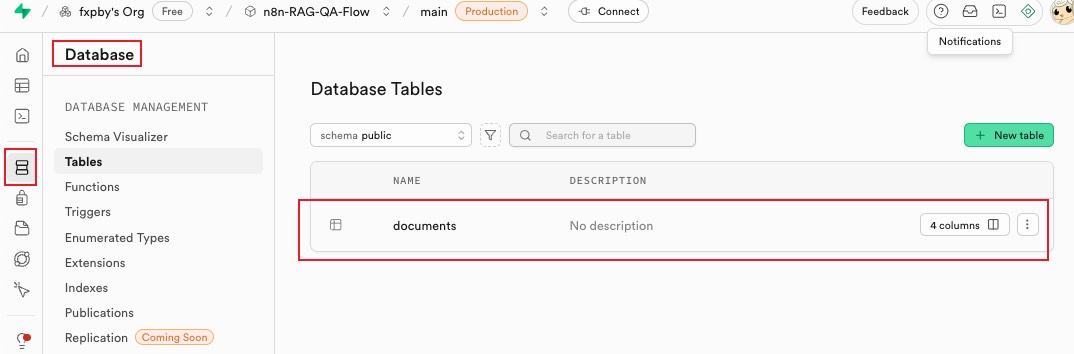
至此 supabase 项目创建完成~
2. 创建导入文档工作流
这个文档工作流主要负责的是将文档数据提交,并将其插入到 supabase 向量存储中
首先来到我们的 n8n 项目,create credential
选择 supabase
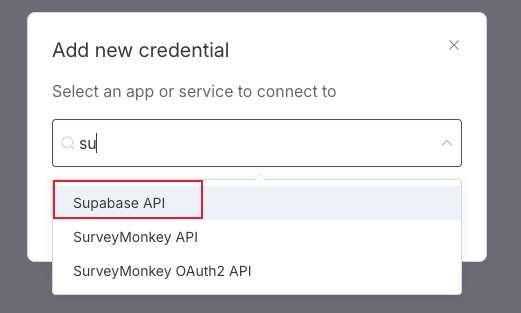
把之前 supabase 中记录的 project URL 和 API Key 拿过来粘贴并保存
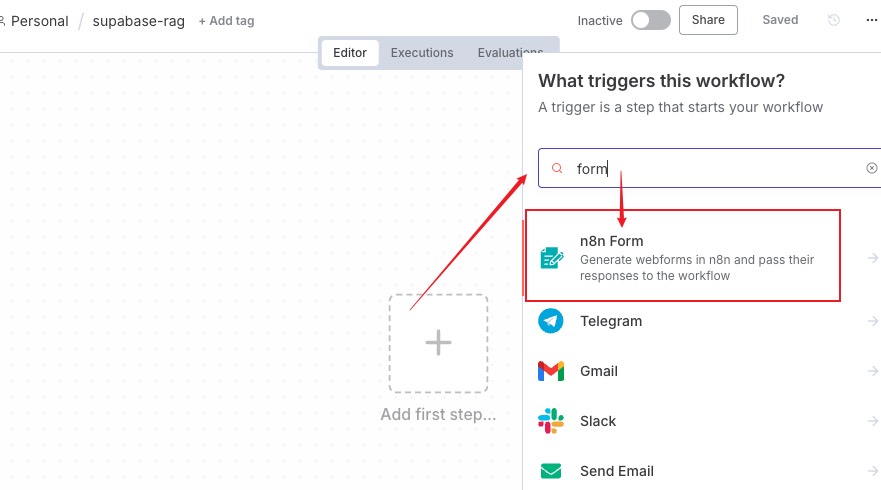
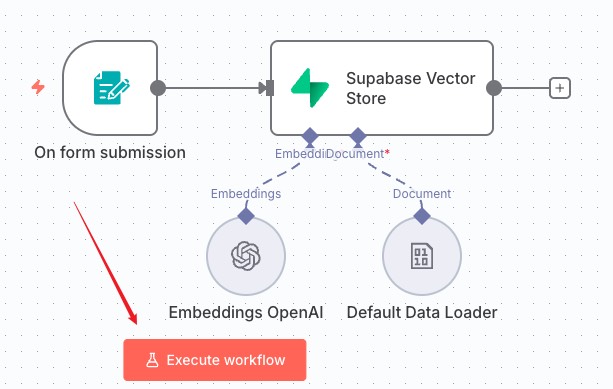
然后我们新建一个工作流,第一个节点触发器选择 n8n Form,我们来设计一个表单
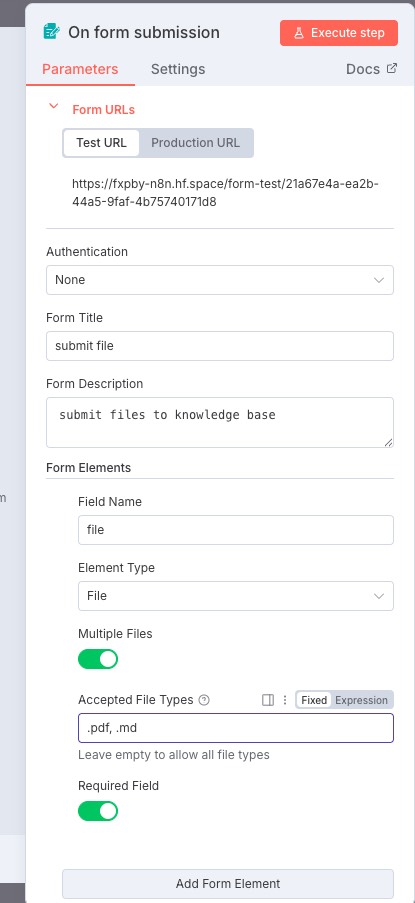
表单设置如图所示
接下来我们添加一个 sqlite 向量存储节点,搜索 supabase,选择 Supabase Vector Store
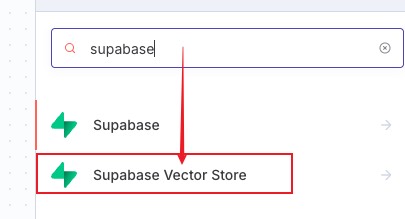
选择第二个向向量存储中添加文档选项
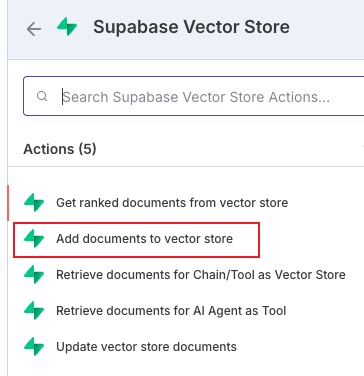
配置如图所示,选择我们之前的项目名称以及表
配置好后会发现节点右下角有一个红色感叹号,这是因为向量存储要依赖的相关组件我们还没有配置添加
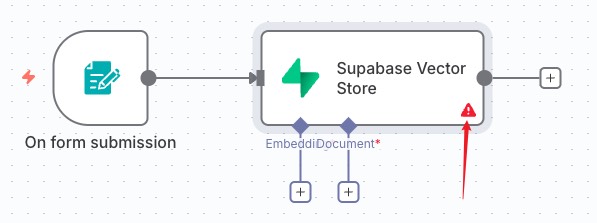
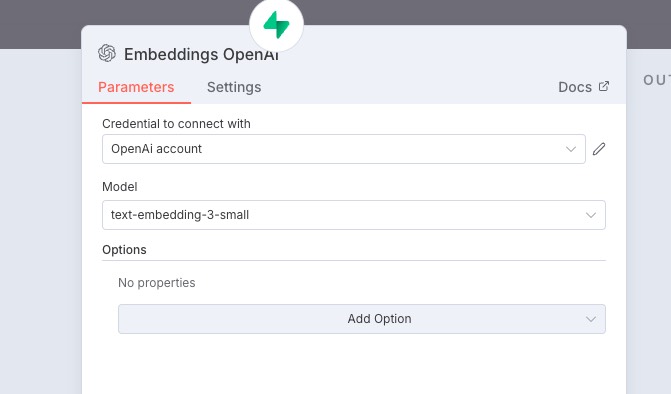
点击左边的 embeddings 节点,这里选择了 openAI 的
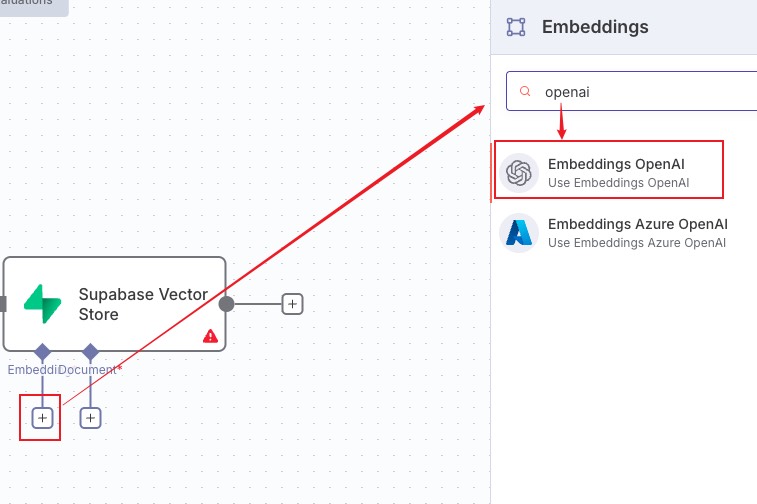
没有证书配置的话需要设置一下,这里自己用了 (后面改成另外的模型了)openrouter 的
openrouter embeddings 节点不适用于 n8n,n8n 只接受标准模型。于是搞了张虚拟卡注册了 cohere 的账号来跑的
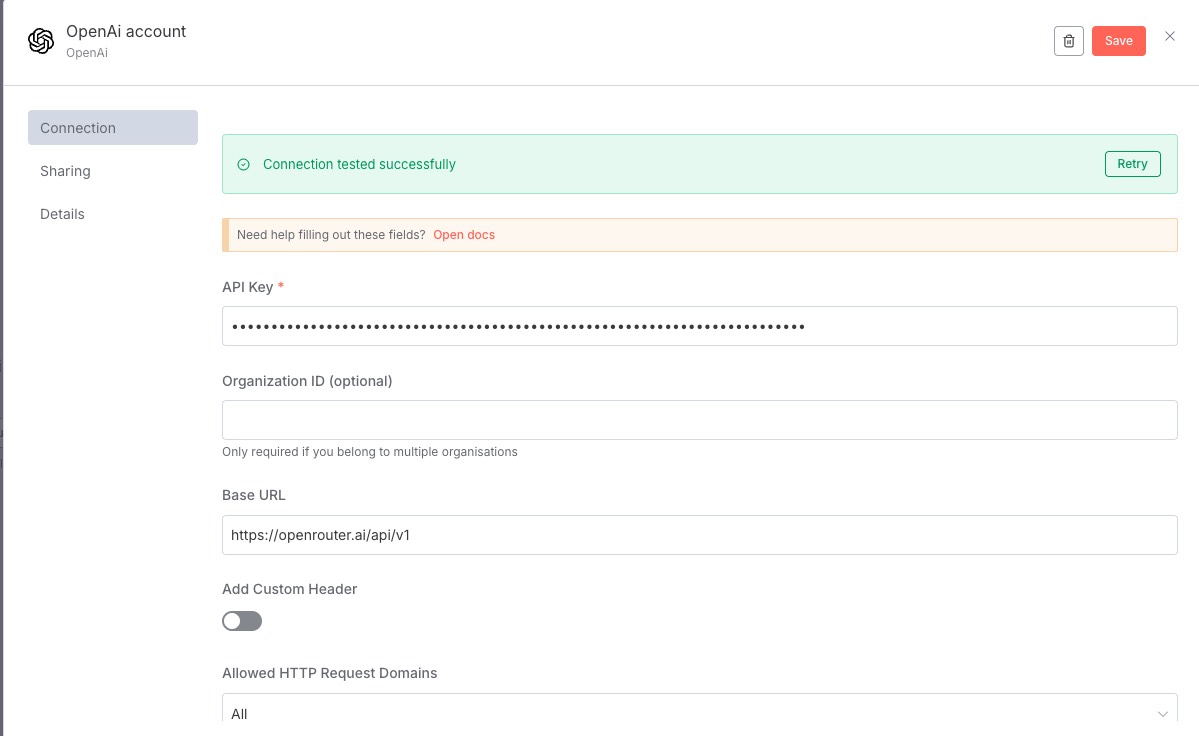
配置好如图所示
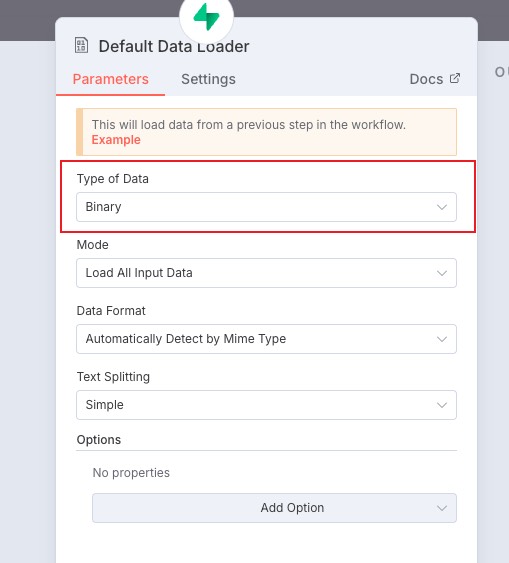
然后点击第二个加号节点 document 添加我们的数据加载器,选择第一个 default Data Loader
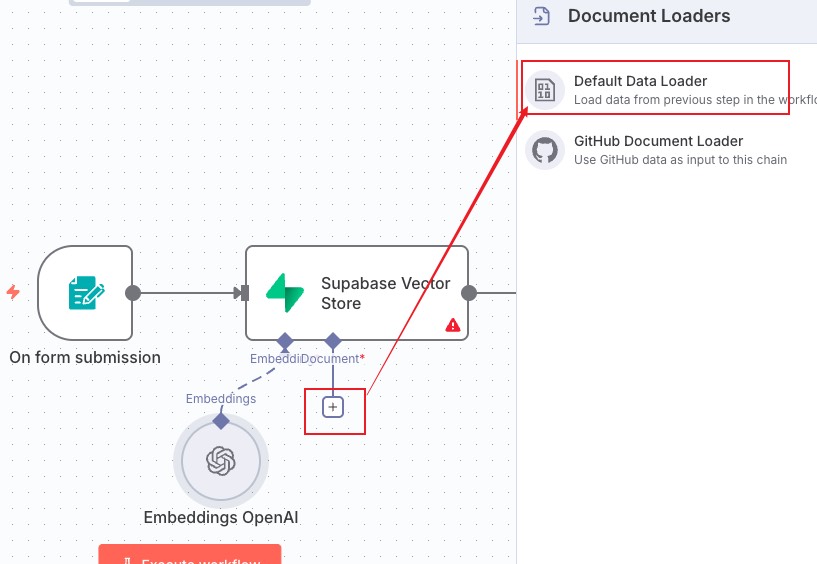
如图配置,其中 Type of Data 由于是文件,我们选择 binary
文本拆分有两种模式,一个是简单模式,一个是自定义模式。简单模式是每 1000 个字符做拆分,然后包含 200 字符的重叠,我们保持 simple
然后就可以点击下方按钮测试了
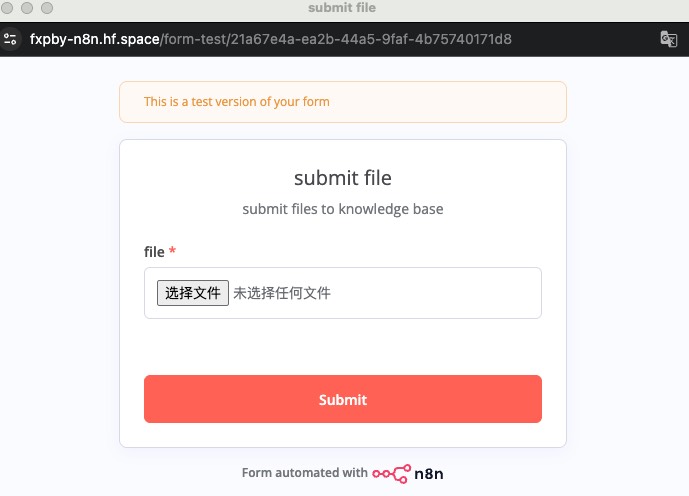
选择文件,这里选了个讲设计模式的 PDF 文件简单介绍 promise 的文件(跑流程换了个小的)
提交完成提示如图
然后就可以看到工作流开始流转了(embeddings 换成 cohere 了)
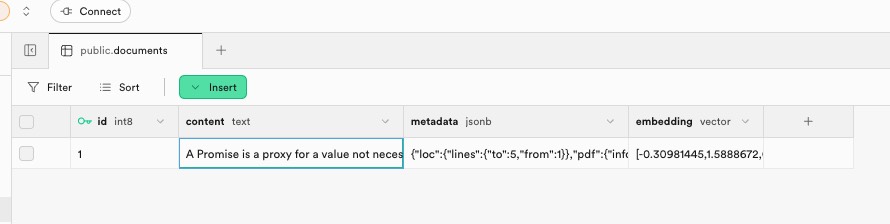
流转完成后我们回到 supabase 控制面板查看表数据
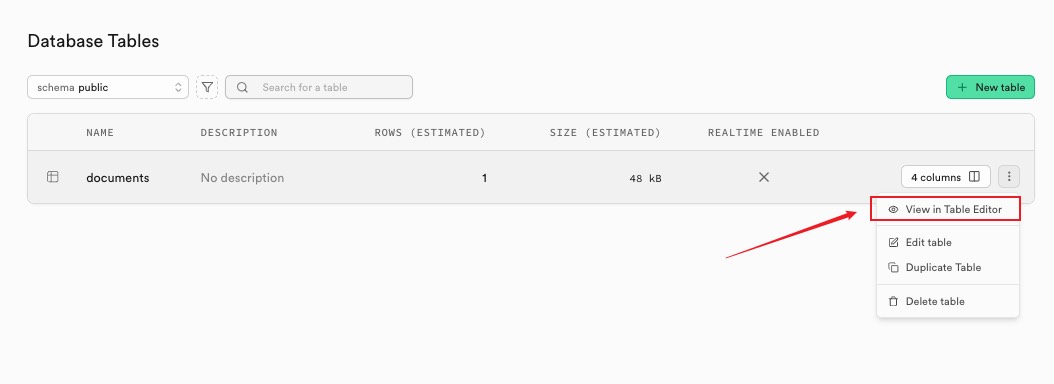
可以看到新数据了,自己 PDF 文件就一页所以数据比较少只有一条记录
- content:是对文档的分块后的切片的原始内容
- embedding:是它的向量数据
- Metadata:是每一个文档分块的原数据
至此就完成了第一个工作流~
3. 创建知识库问答工作流
这个工作流是基于向量存储来进行问答的,首先先完成对相关文档的检索,再基于文档分块,由大模型完成推理
我们新创建一个工作流,并添加一个聊天触发器节点
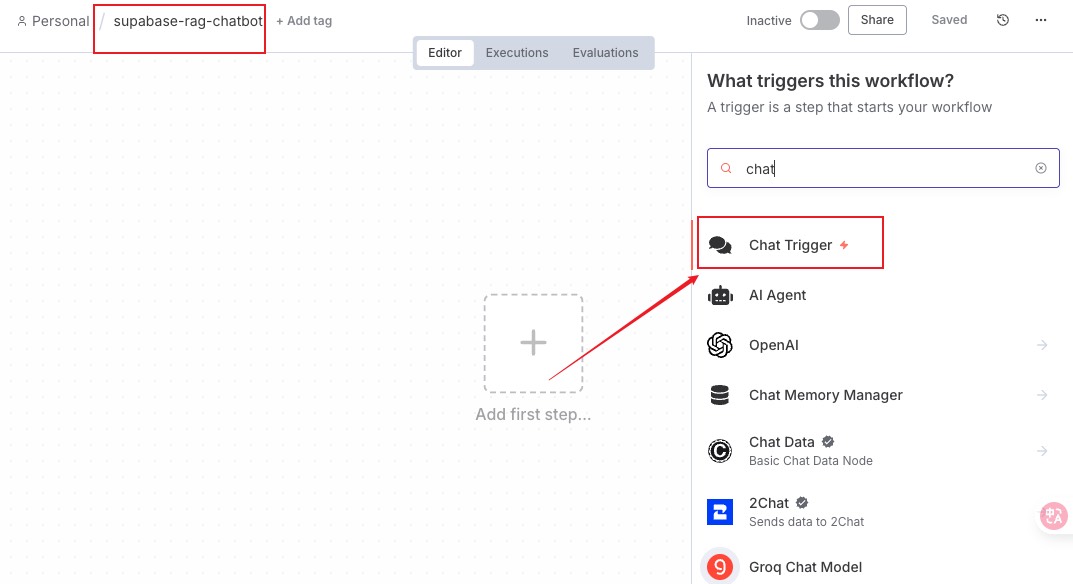
接着给聊天触发器添加一个 AI Agent
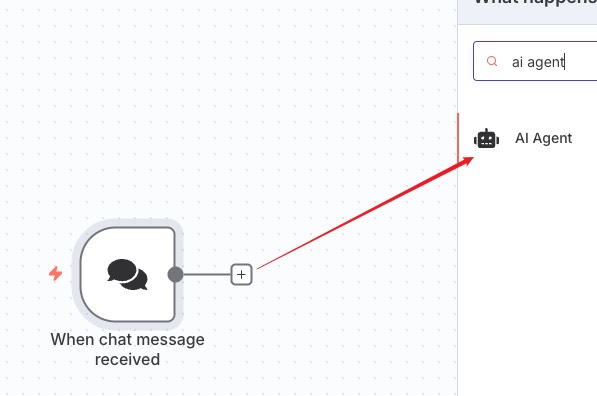
这里模型结合手头有的自行选择,笔者选择的是 openrouter也换成 cohere 了,openrouter 后面接其他节点工具用不了会报错 No endpoints found that support tool use. To learn more about provider routing, visit: https://openrouter.ai/docs/provider-routing,很可惜吧,没有适配 n8n
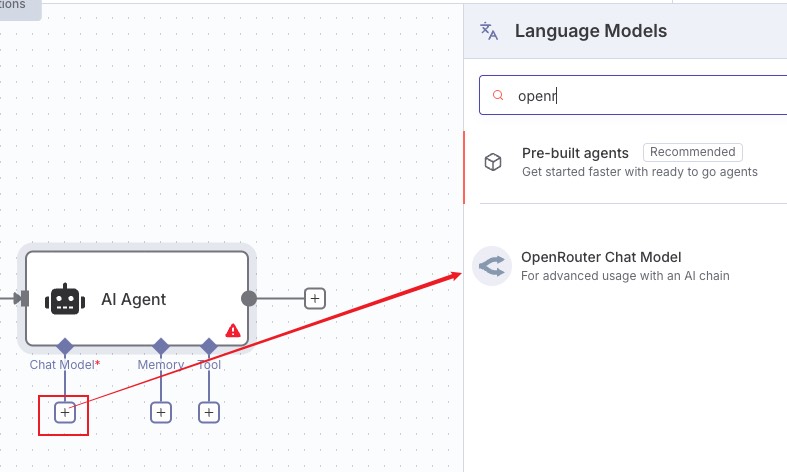
提前配置好证书哦,选了个免费模型~
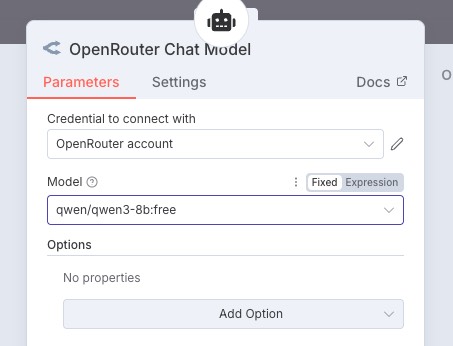
接入完成简单测试一下聊天功能,运行完美~
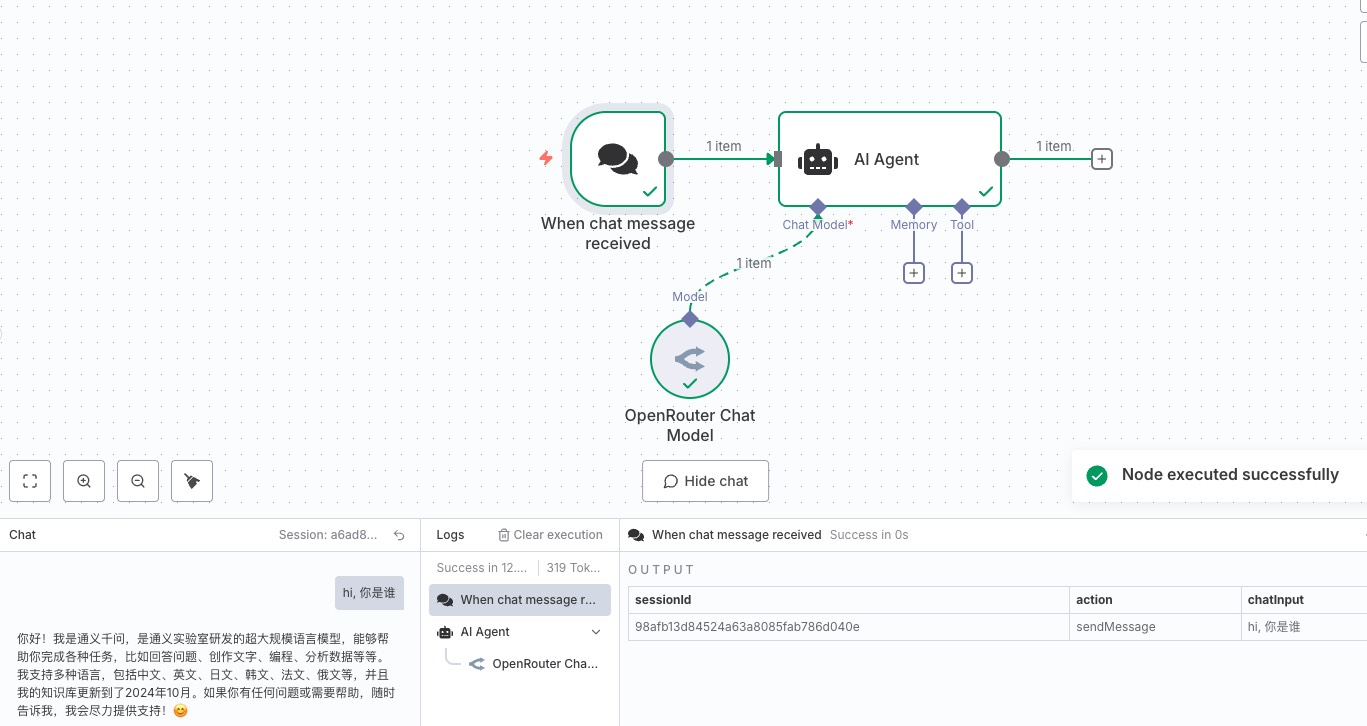
然后给 AI Agent 添加 Tool,搜索选择 Supabase Vector Store
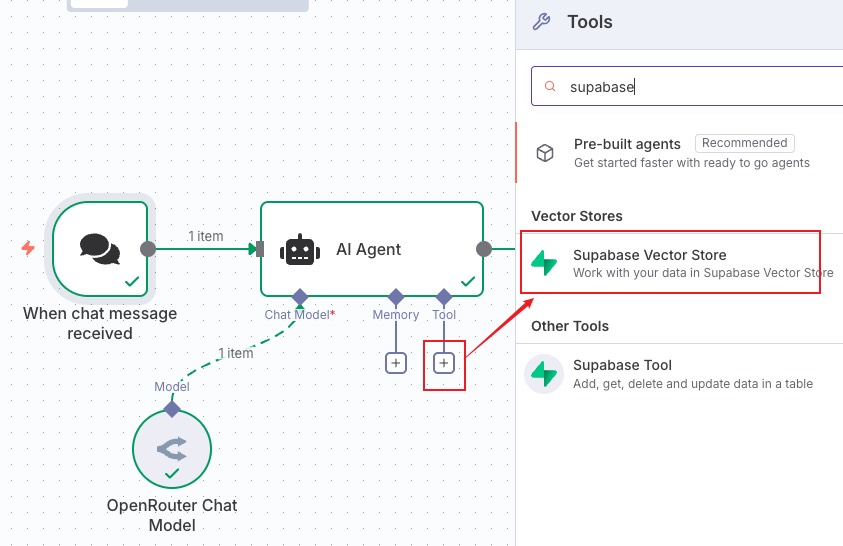
配置如图,选择 documents。limit 表示检索多少份文档,可以根据自己的需要来调整参数,这里保持默认
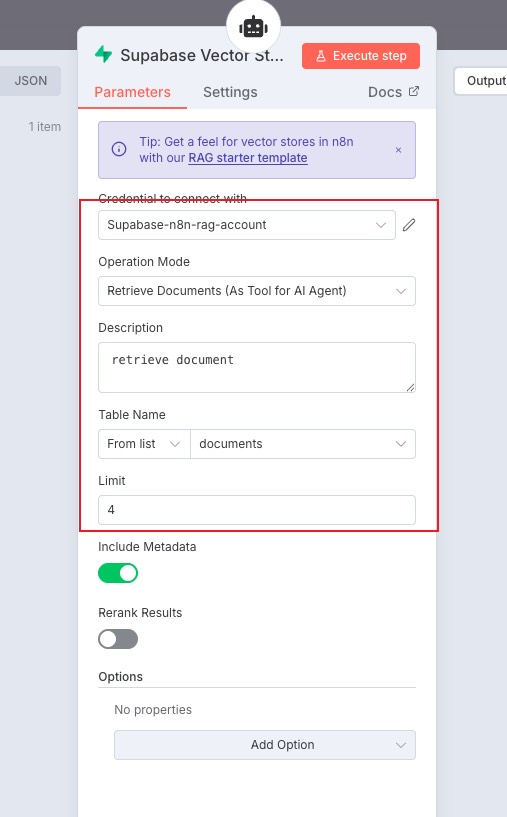
至此这个工作流就构建完成了,我们将 supabase 作为向量存储工具集成到 AI Agent
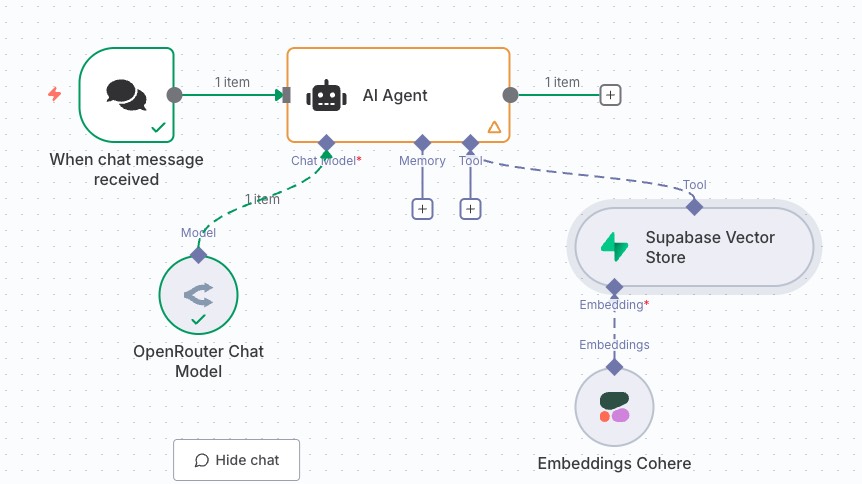
工作流流转中
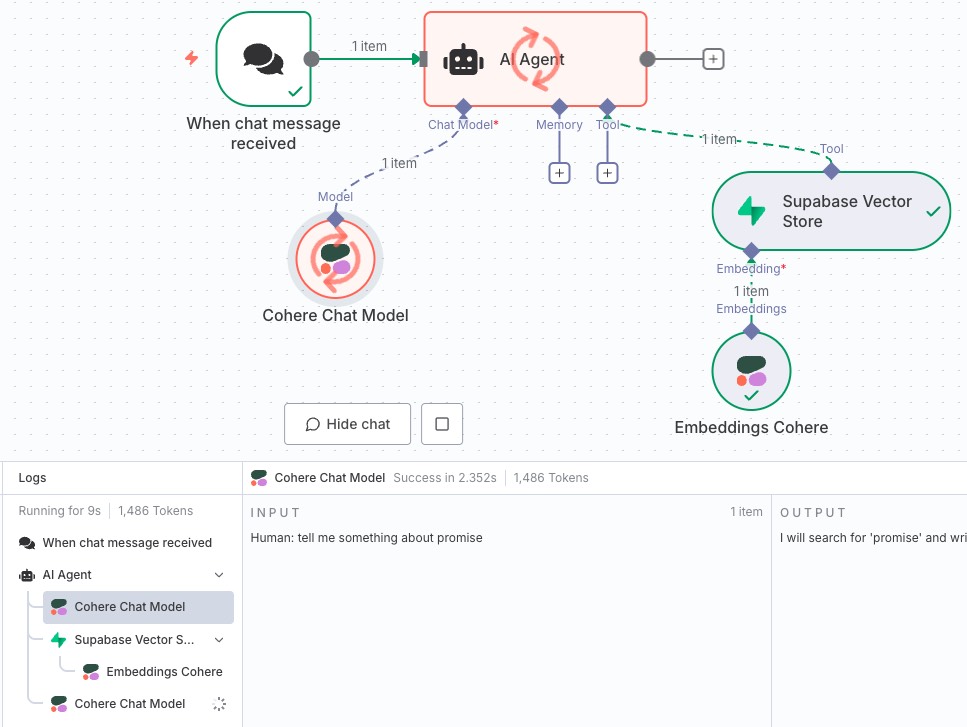
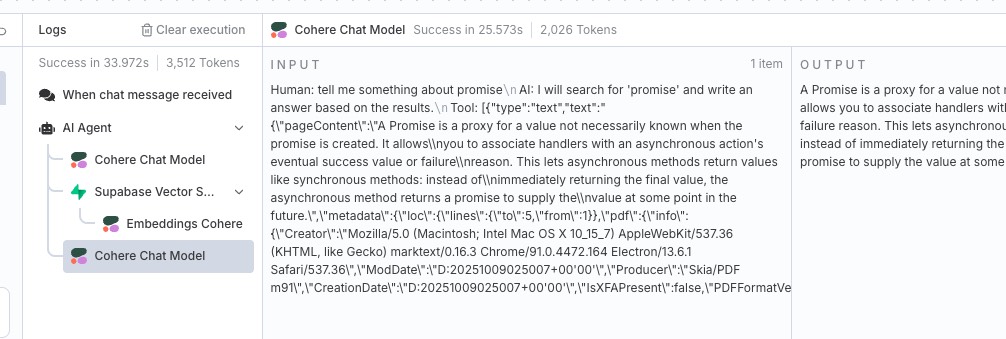
流转执行完成,可以看到聊天窗口展示的内容和前面提交存储到数据库中的文案一致
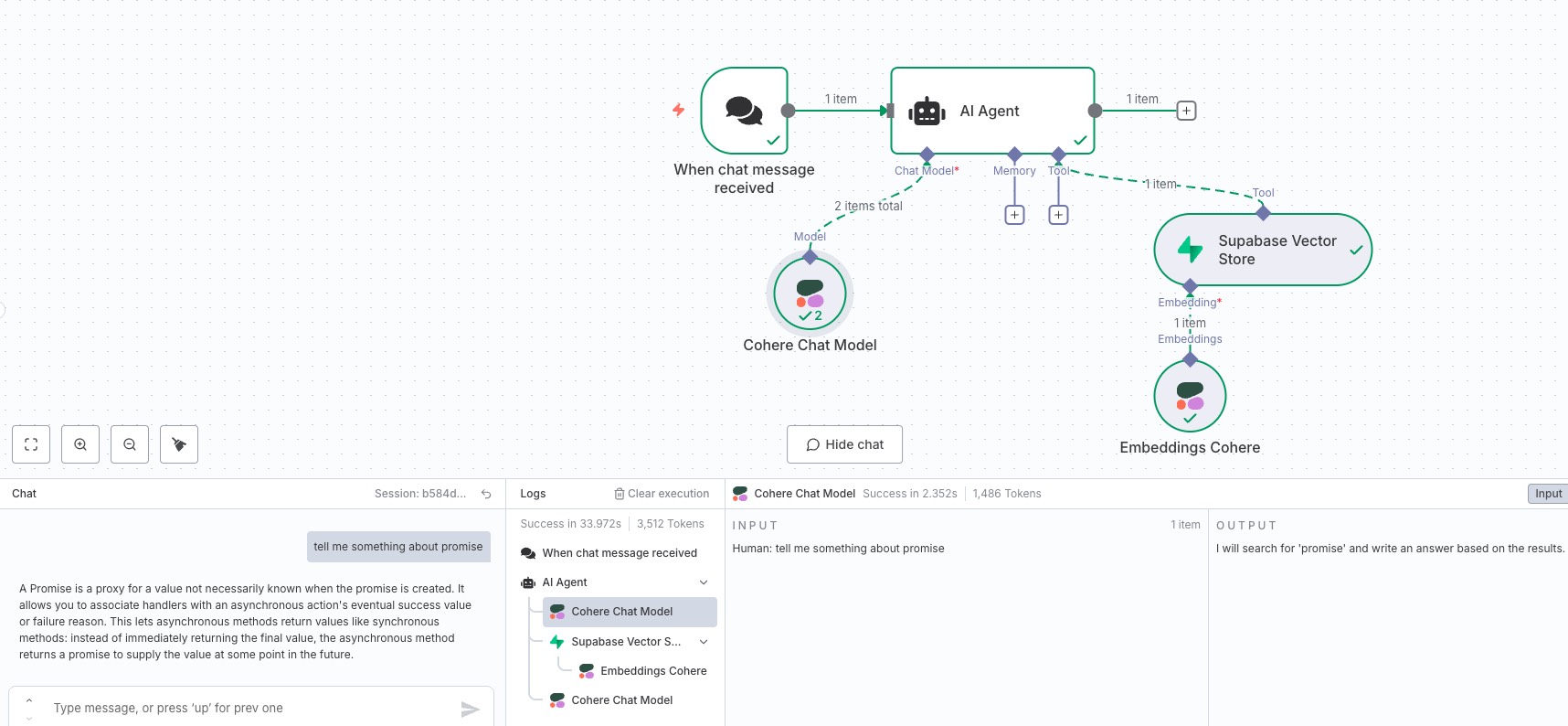
点击下方的 LLM 模型调用可以看到 Tool 中,Supabase Vector Store 给我们的文档分块的引用,LLM 模型把这些文档分块作为了输入
至此我们的知识库问答工作流也完成了~🥳