
浏览器渲染原理
1. 浏览器的渲染流程
1.1 渲染时间点
浏览器的网络进程开启线程接收 HTML 文档,产生一个渲染任务并传递给渲染主线程的消息队列,在事件循环机制作用下,渲染主线程取出消息队列中的渲染任务,开启渲染流程

1.2 渲染流水线
整个渲染流程分为多个阶段,分别是
- HTML 解析
- 样式计算
- 布局
- 分层
- 生成绘制指令
- 分块
- 光栅化
- 画
每个阶段都有明确的输入输出,即上一阶段的输出会成为下一阶段的输入,综上整个渲染流程形成了一套组织严密的生产流水线


来自 google 的图:

1.3 Parse 阶段:解析 HTML
解析过程遇到 CSS 解析 CSS,遇到 JS 解析 JS,为了提高解析效率,浏览器在开始解析前会启动一个预解析线程,率先下载 HTML 中的外部 CSS 和 JS 文件
- 如果主线程解析到
link位置,此时外部 CSS 文件还没有下载解析好,主线程不会等待,继续解析后续的 HTML(下载和解析 CSS 的工作在预解析线程中进行)- CSS 不会阻塞 HTML 解析 - 如果主线程解析到
script位置,会停止解析 HTML,转而等待 JS 文件下载好,并将全局代码解析执行完成后,才能继续解析 HTML(JS 代码的执行过程可能会修改当前的 DOM 树,故 DOM 树的生成必须暂停)- JS 会阻塞 HTML 解析
最终得到 DOM 树和 CSSOM 树, 浏览器的默认样式、内部样式、外部样式和行内样式均会包含在 CSSOM 树中,树的每个节点都对应 JS 对象
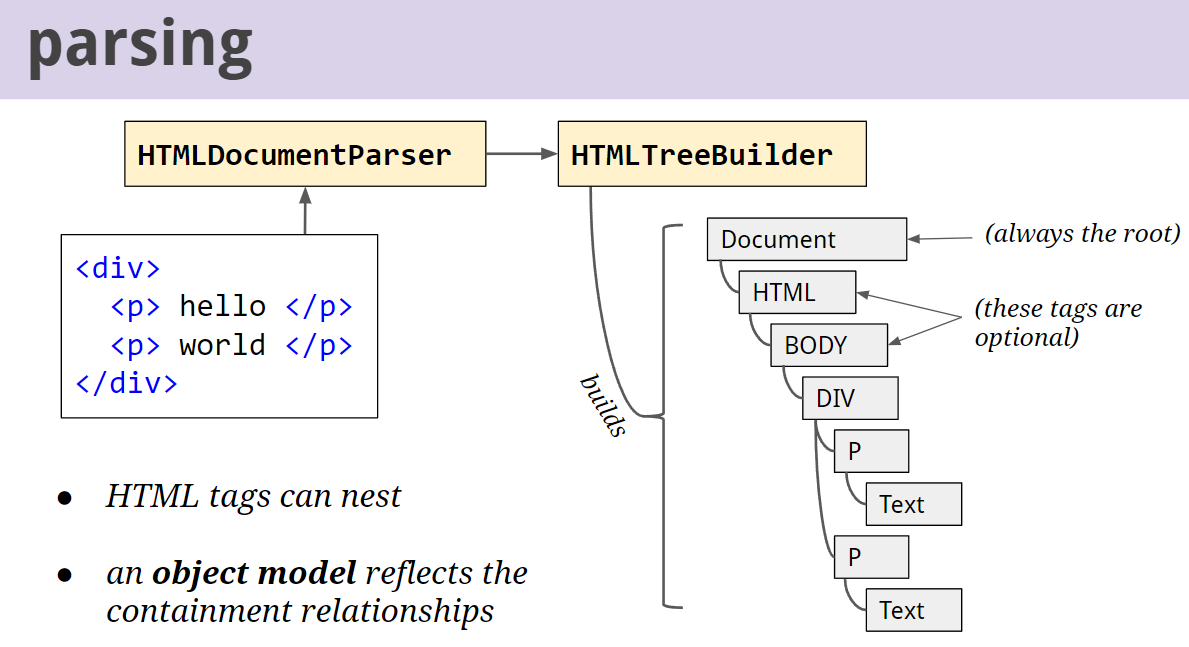
DOM 树(文档对象模型)
Bytes => Characters => Tokens => Nodes => DOM
- 转换 Conversion:浏览器从磁盘或网络中读取 HTML 原始字节,并根据文件的指定编码(如 UTF-8)将它们转换为各个字符
- 令牌化/分词 Tokenizing:浏览器根据 HTML 规范将字符串转换为不同令牌(如
<html>、<body>)以及用尖括号括起来的其他字符串 - 词法处理/语法分析 Lexing:上一步产生的标记被转换为“对象”,从而定义其属性和规则
- DOM 构建:由于 HTML 标记定义了不同标签之间的关系,因此创建的对象链接在一个树型数据结构中,并捕获原始标记中定义的父子、兄弟关系
CSSOM 树(CSS 对象模型)
重复上面 DOM 树流程,针对 CSS
StyleSheetList(样式表集合) => 若干个样式表 CSSStyleSheet => CSSStyleRule => 选择器 + style
样式表分类:
- 头部
<style>样式表 - 头部
<link...>样式表 - 内联样式表
<div style="color: #fff"> - 浏览器默认样式表(user agent stylesheet)
除了浏览器默认样式,其他样式 js 都可以操作,比如 内联样式通过 dom.style 更改, 前两个样式可通过 document.styleSheets[0].addRule('div', 'border: 1px solid red')处理
Bytes => Characters => Tokens => Nodes => CSSOM
https://web.dev/articles/critical-rendering-path/constructing-the-object-model?hl=zh-cn
CSSOM 和 DOM 并行构建,构建 CSSOM 不会阻塞 DOM 构建。因为 JS 可能会操作样式信息,故 CSSOM 会阻塞 JS 执行
虽然 CSSOM 不会阻塞 DOM 构建,但进入下一阶段之前,必须等待 CSSOM 构建完成,即 CSSOM 会阻塞渲染
HTML 解析过程遇到 CSS/JS 代码(次级资源加载)
一个网页可能会有多个外部资源,如图片、js、css、字体等。主线程在解析 DOM 过程中遇到这些资源后会一一请求
为了加速渲染流程,预加载扫描器(preload scanner)线程并发运行。如果 HTML 中存在 img 或 link 等内容,预加载扫描器会查看 HTML parser 生成的标记,并发送请求到浏览器进程的网络线程获取资源
次级资源加载-css

次级资源加载-js

1.4 Style 阶段:样式计算
主线程会遍历得到的 DOM 树,依次为树中的每个节点计算出最终的样式,即 Computed Style
样式属性计算过程中,很多预设值会变成绝对值,如 red 会变成 rgb(255, 0, 0), 相对单位会变成绝对单位,em 会变成 px
计算完成后会得到一颗带有样式 DOM 树
CSS 引擎处理样式过程:
- 收集、划分和索引所有样式表中存在的样式规则,CSS 引擎会从 style 标签,css 文件及浏览器代理样式中收集所有的样式规则,并为这些规则建立索引,方便后续高效查询
- 访问每个元素并找到适用于该元素的所有规则,CSS 引擎遍历 DOM 节点,进行选择器适配,为匹配的节点执行样式设置
- 结合层叠规则和其他信息为节点生成最终的计算样式,这些样式值可以通过
window.getComputedStyle()获取
页面样式多的话,即存在大量 CSS 规则,如果为每一个节点都保存一份样式值,会导致内存消耗过大。故 CSS 引擎通常会创建共享的样式结构,计算样式对象一般有指针指向相同的共享结构
1.5 Layout 阶段: 布局
布局完成会得到布局树,收集所有可见的 DOM 节点,以及每个节点的所有样式信息
布局阶段会依次遍历 DOM 树的每一个节点,计算每个节点的几何信息,产出可见节点,包含其内容和计算的样式
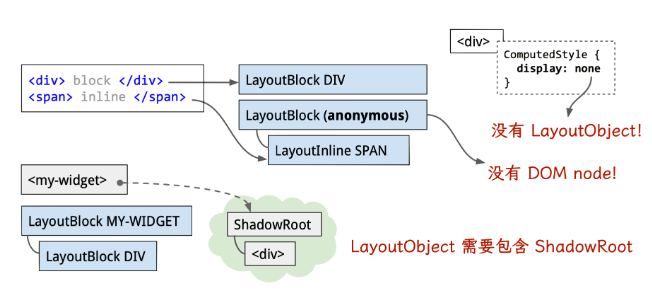
大部分场景下,DOM 树和布局树不是一一对应的:
- 如某些不可见节点(script、head、meta 等)不会体现在渲染输出中,会被忽略
- 如
display: none节点没有几何信息,不会对应生成到布局树 - 如使用了伪元素选择器,虽然 DOM 树中不存在伪元素节点,但是拥有几何信息最终会生成到布局树中(为伪元素创建 LayoutObject)
- 匿名行盒和匿名块盒都会导致 DOM 树和布局树无法一一对应(为行内元素创建匿名包含块对应的 LayoutObject)
布局计算
计算可见节点和其样式后,需要计算它们在设备视口内节点的宽高、相对包含块的位置,这个过程称为自动重排
- 根据 CSS 盒模型及视觉格式化模型,计算每个元素的各种生成盒的大小和位置
- 计算块级元素、行内元素、浮动元素、各种定位元素的大小和位置
- 计算文字,滚动区域的大小和位置
- LayoutObject 类型:
- 传统的 LayoutObject 节点会把布局运算的结果重新写回布局树中
- LayoutNG (Chrome 76 开始启用)节点的输出不可变,会保存在 NGLayoutResult 中,是一个树状结构,相比 LayoutObject 减少很多回溯计算,提高性能

1.6 Layer 阶段: 分层
主线程会使用一套复杂的策略对整个布局树中进行分层
分层的好处在于,将来某一个层改变后,仅会对该层进行后续处理,提高效率
滚动条、堆叠上下文、transform、opacity 等样式均会影响分层结果,还可以通过 will-change 更大程度影响分层结果
构建 PaintLayer(RenderLayer) 树
构建完成的 layoutObject 树不可以被拿去显示(不包含绘制顺序 z-index),还有一些复杂情况如 3d 变换,页面滚动等,浏览器会对上一步的节点进行分层处理 - 建立层叠上下文
浏览器根据 CSS 层叠上下文规范,建立层叠上下文
- DOM 树的 Document 节点对应的 RenderView 节点
- DOM 树的 Document 节点的子节点,即 HTML 节点对应的 RenderBlock 节点
- 显式指定 CSS 位置的节点(position 为 absolute 或 fixed)
- 具有透明效果的节点
- 具有 CSS 3D 属性的节点
- 使用 Canvas 元素或者 Video 元素的节点
浏览器遍历 LayoutObject 树的时候,建立了 PaintLayer 树,LayoutObject 和 PaintLayer 不一定一一对应,即每个 LayoutObject 要么和自己的 PaintLayer 关联,要么和拥有 PaintLayer 的第一个祖先元素的 PaintLayer 关联
构建 cc::Layer 与 display items
浏览器会继续根据 PaintLayer 树创建 cc::Layer 列表,cc::Layer 是列表状结构,运行在主线程,一个渲染进程内有且只有一个 cc::Layer,代表一个矩形区域内的 UI,layer 里有 DisplayItem 列表,是绘制操作的列表,包含实际的 paint op 指令。将页面分层,可以让一个图层独立于其他的图层进行变换和光栅化处理
- 合成更新(Compositing update)
- 依据 PaintLayer 决定分层
- 这个策略被称为 CompositeBeforePaint,未来会被 CompositeAfterPaint 替代
- PrePaint
- PaintInvalidator 进行失效检查,找出需要绘制的 display items
- 构建 paint property 树,使动画、页面滚动,clip 等变化仅在合成线程运行,提高性能
1.7 Pre-Paint 阶段:生成绘制指令
主线程会为每个层单独产生绘制指令集,用于描述这一层的内容该如何画出来
DisplayItem 列表准备好后,渲染主线程会给合成线程发送commit消息,即将每个图层的绘制信息提交给合成线程,剩余工作将由合成线程完成(渲染主线程任务至此告一段落)
1.8 Tiling 阶段:分块
合成线程先对每个图层进行分块,将其划分为更多的小区域,再从线程池中拿取多个线程来分块工作
分块的原因:
考虑到视口大小,当页面非常大的时候,要滑动很长时间,这样一次性全部绘制是十分浪费性能的,因此需要将图层分块,进而加速页面首屏展示

1.9 Raster 阶段: 光栅化
合成线程将块信息交给 GPU 进程,将每个块变成位图(像素信息-像素点、颜色等),GPU 进程会开启多个线程完成光珊瑚,且优先处理靠近视口的块


1.10 画
合成线程拿到每个层、每个块的位图后,生成一个个 quad 指引信息
指引会标识出每个位图应该画到屏幕的哪个位置(如考虑旋转、缩放等变形)
变形发生在合成线程,与渲染主线程无关(即 transform 高效率的本质)
合成线程把 quad 提交给 GPU 进程,由 GPU 进程产生系统调用,提交给 GPU 硬件,完成最终的屏幕成像

2. 浏览器渲染性能优化
我们在修改元素几何信息时,实际修改的是 CSSOM 或 DOM
2.1 reflow
重排对应浏览器渲染过程中的 Layout, 其本质是重新计算 layout 树
为了避免连续多次操作导致布局树反复计算,浏览器会合并这些操作,当 js 代码全部完成后再进行统一计算,即改动属性造成的 reflow 是异步完成的,这也就导致了,在 js 获取布局属性时,可能会造成无法获取到最新布局信息的问题。为了解决这个问题浏览器便有了使用 js 获取属性时产生一个同步任务会立即 reflow 的机制(设置属性异步,读取属性同步)
2.2 repaint
重绘对应浏览器渲染过程中的 Paint, 其本质是重新根据分层信息计算绘制指令
改变可见样式后小重新计算,就会触发 repaint
元素的布局信息也属于可见样式,从上面的流程图中我们可以发现 Layout 改变一定会触发 Paint,即重排一定会触发重绘
更具体的内容请参考这篇总结 浏览器的重排和重绘
reference
- https://web.dev/articles/critical-rendering-path/constructing-the-object-model?hl=zh-cn
- https://web.dev/articles/critical-rendering-path/render-tree-construction?hl=zh-cn
- https://www.lambdatest.com/blog/css-object-model/
- https://web.dev/articles/howbrowserswork?hl=zh-cn
- https://me.ursb.me/archives/360.html#directory03020959219799874718
- https://cansiny0320.vercel.app/browser-render-process
- https://fed.taobao.org/blog/taofed/do71ct/performance-composite/